项目地址:https://github.com/Jiahonzheng/Robotics/tree/master/HW4
任务概要
-
在给定的赛道中,实现多车道的避障和视觉巡线。
-
避障算法没有限定,可使用人工势场、RRT等路径规划算法。
-
车体大小、赛道信息以及参考资料在此处下载。
完成情况
- 已学习并能初步使用 V-REP Python Remote API 接口,实现 Python 与 V-REP 的功能交互。
- 已实现基于视觉传感器的多车道巡线功能。
- 已实现基于视觉传感器的多车道避障功能。
V-REP Python Remote API
由于在上次实验中,我们已初步尝试 V-REP Remote API 接口的使用,积累了部分经验,并且考虑到本次实验任务的复杂性,因此在本次实验中,我们使用 V-REP Python Remote API 构建机器人的多车道巡线和避障算法。
首先,我们为机器人模型添加 Non-threaded Script ,其具体内容如下。在 sysCall_init 函数中,我们在端口 19999 开启了 Remote API 服务。

为了成功使用 Python 与 V-REP 交互,我们需要导入 remoteApiBindings 至项目文件夹,具体目录为 V-REP 安装目录下的 programming\remoteApiBindings ,我们只需导入 vrep.py、vrepConst.py 和 remoteApi.dll 文件。我们编写简单的 Python 代码,测试 Remote API 是否调用成功,具体代码如下。

点击 V-REP 仿真运行按钮,随后执行上述脚本,若无发生异常,说明 Remote API 建立成功。
我们可通过 vrep.simxGetObjectHandle 获取 V-REP 仿真环境下的物体句柄。

工具函数
在实现中,我们封装了一些可复用的工具函数,如pid_controller、motor、steer、get_image等函数。
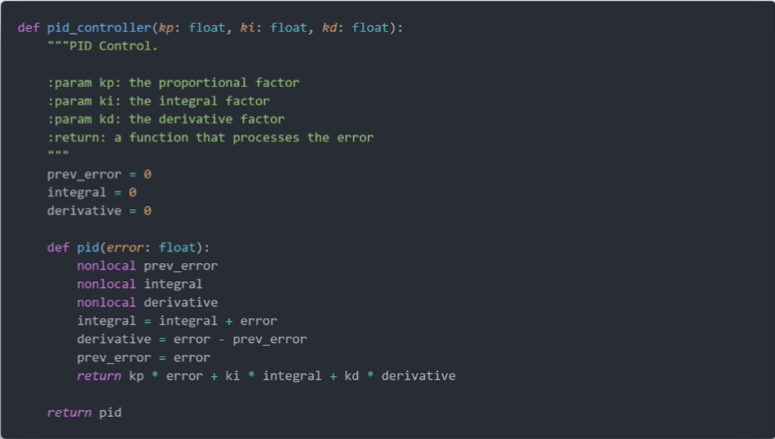
在 PID 控制中,我们输入偏差量,输出调节量,涉及到 3 个控制器的参数 kp、ki、kd。因此,我们使用 Python Clousure 技术封装 PID 控制单元,具体代码如下。在 pid_controller 函数中,我们接收 3 个控制器参数,输出一个函数,该函数接收偏差量输入,输出调节量。
为了控制前进电机的动力输出,我们封装了 motor 工具函数,具体代码如下。该函数接收速度大小,调用 simxSetJointTargetVelocity 方法控制电机的动力输出。

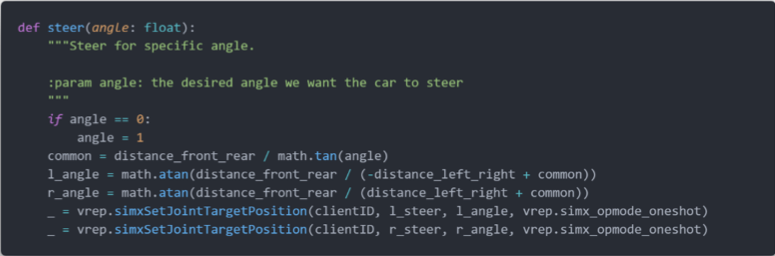
在实验中,我们使用 Ackermann 作为机器人的运动学模型。在该模型下,对于一个转向角度,两个转向轮的转向角度是需要根据运动学模型计算出来的。为此,我们实现了 steer 工具函数。
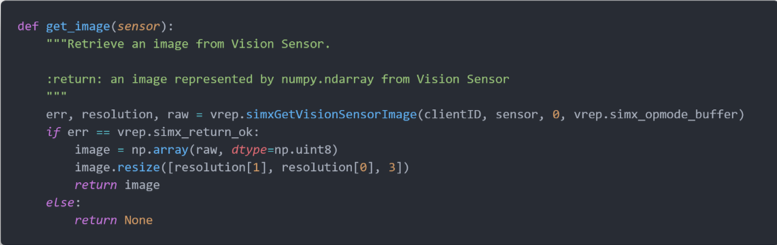
由于本次实验的目的是使用视觉传感器实现多车道的巡线和避障,因此从视觉传感器获取图像的过程是重要的,也是可复用的。这里,我们实现了 get_image 工具函数。在该函数中,我们调用 simxGetVisionSensorImage 方法,获取指定视觉传感器的图像,并调用 numpy 处理原数据,返回可供我们操作的图像数据。
多车道巡线
为了实现机器车的多车道巡线,我们采取以下的视觉巡线策略:获取每一帧图像,确定图像的最大连通区域,并计算其几何中心,从而计算偏向角度。
首先,我们调用 get_image 获取 Lane Vision Sensor 的图像。

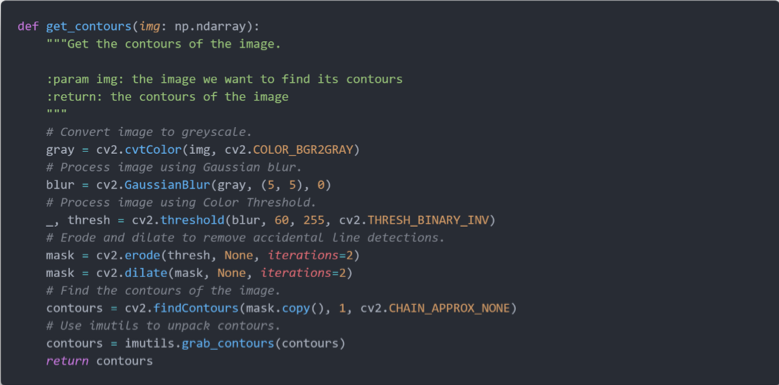
随后,我们调用 get_contours 方法确定图像上的连通区域。在此方法中,我们首先对图像进行灰度处理,随后进行高斯模糊、二值化、腐蚀和膨胀处理,最后我们调用 OpenCV 的 findContours 方法,确定图像的连通区域。注意到,我们最后使用了 imutils 处理 contours 数据,这是出于数据格式转换的目的。
在获取到图像的所有连通区域后,我们找出最大的连通区域,计算它的几何中心,随后根据几何中心的坐标,我们计算偏向角度,具体代码如下。
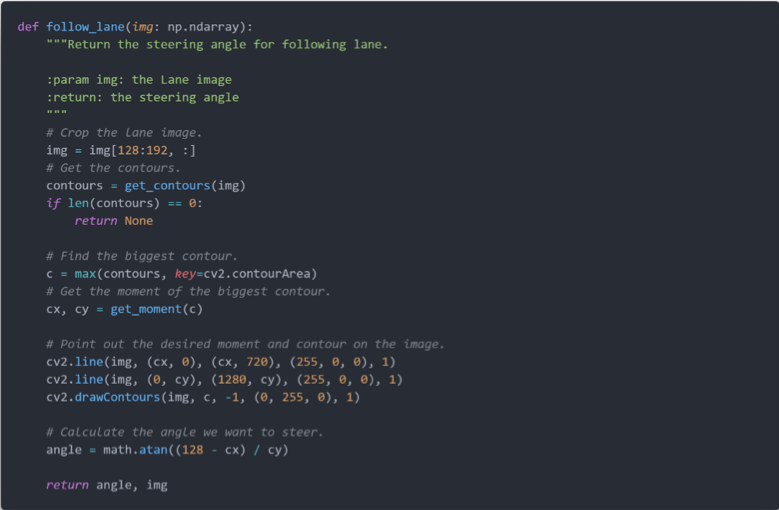
以下是多车道巡线算法的核心流程:根据图像获取转向角度,从而实现视觉巡线。
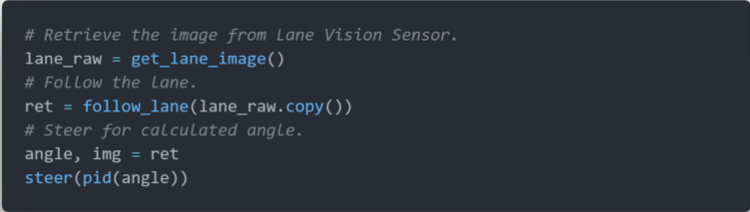
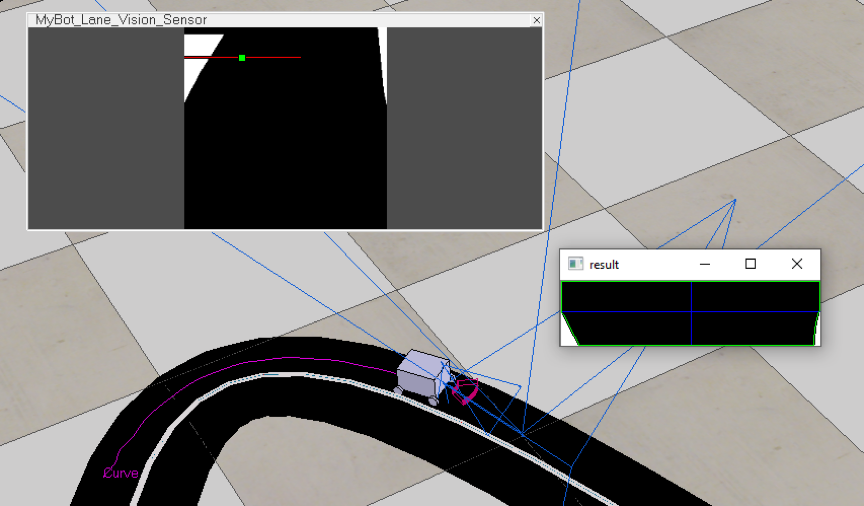
算法实际运行情况如下图所示,我们可以看到标题为 result 的窗口,这显示当前连通区域的几何中心。
多车道避障
为了实现机器车的多车道避障,我们使用以下的避障策略:获取每一帧图像,确定当前车道和其他车道。当在当前车道遇到障碍物时,转弯进入其他车道,从而避障。
首先,我们调用 get_image 获取 Obstacle Vision Sensor 的图像。
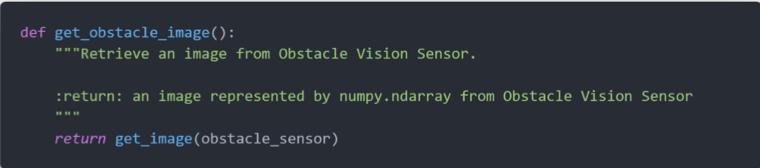
我们在 get_other_lane 函数中实现了在图像中识别当前车道和其他车道的功能,具体思路是:确定图像的连通区域,并对其进行从大到小的排序,随后判断车辆当前点位于哪一个较大的连通区域,该区域即为当前车道,而不含车辆当前点的最大连通区域即为其他车道。
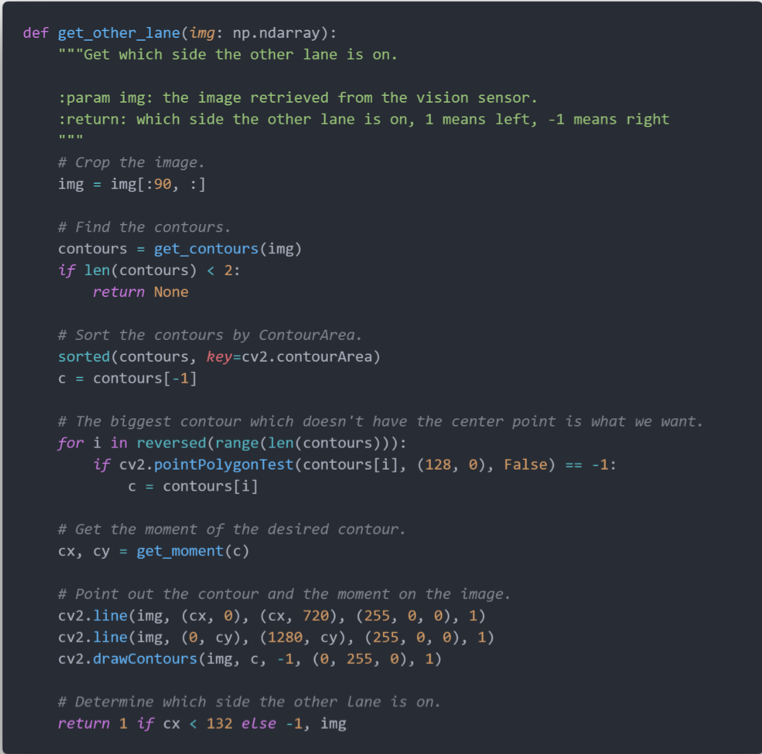
以下是多车道避障算法的核心流程:当在当前车道检测到障碍物时,根据图像确定从当前车道转至其他车道的方向,从而实现避障。
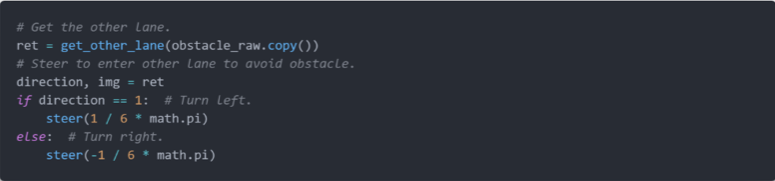
以下是多车道巡线和避障算法的实际运行情况。

在本次实验中,我们一开始尝试使用人工势场方法实现视觉避障功能,但由于能力原因,并未成功将其实现。我们的基本思路是:利用内参矩阵对视觉传感器返回的图像进行变换,得到图像中的点在世界坐标系的表示,随后应用人工势场方法,目标点选取在障碍物后,得到避障路线。在实现过程中,我们在对图像中的障碍物的识别过程遇到了难以解决的问题,因此放弃了此方案。
效果展示
多车道巡线
以下是机器人的静态演示图,位于车顶的是视觉传感器,用于多车道巡线功能。

下面是机器人多车道巡线的示意图,详细细节可参考视频:https://www.bilibili.com/video/av71601540 。

多车道巡线和避障
以下是多车道巡线和避障机器人的静态演示图。

下面是机器人多车道巡线和避障的示意图,详细细节可参考视频:https://www.bilibili.com/video/av71600529 。

存在问题
本次实验,内容是多车道巡线和避障的结合,还是颇有挑战性的。我们遇到了几个具备挑战性的问题,最终大多数都被解决了,但仍有遗留问题。
在模型构建上,我们使用了 V-REP Python Remote API 实现机器人的巡线和避障算法,由于在上次实验中,我们已经踩过 Remote API 的坑,所以本次实验我们并未在 Remote API 部分耗费太多时间。
我们将本次实验任务划分为了两部分:多车道巡线、多车道避障。在多车道巡线部分,我们是一开始就确定要从连通区域的几何中心切入。但我们在计算连通区域时,遇到了 OpenCV 接口不兼容的问题,在查阅几篇技术文章后,我们引入了 imutils 包,对 findContours 返回数据进行了封装处理,这才解决了问题。
在多车道避障部分,我们一开始是打算使用内参矩阵对图像进行坐标变换,从而使用人工势场路径规划,计算出避障路线。但由于我们能力原因,并未将其成功实现。但在查阅人工势场相关资料的过程中,我们对该方法有了更为深入的理解,这也算是本次实验的一个大收获。我们使用另一种避障方式:根据 Proximity Sensor 判断是否在当前车道检测到障碍物,若检测到则先确定图像中其他车道的位置(是当前车道的左边还是右边),随后进行避障。在成功将该算法实现后,我们发现其效果挺不错的。但由于我们使用了 Proximity Sensor 探测障碍物,而并未使用视觉障碍物检测,这是我们本次实验没有完成的任务,很遗憾。